数据挖掘相关知识与工具
Python 数据分析工具库:
数组处理:Numpy
-
简介:python 强大的数组库
-
安装:pip install Numpy
-
官网 :
矩阵运算:Scipy
-
简介:提供矩阵运算及大量的基于矩阵运算的数组和对象,它依赖与Numpy,安装前需安装Numpy。功能:最优化、线性代数、积分、插值、拟合、特殊函数、快速傅里叶变换、信号处理、图像处理、常微分方程求解等。
-
安装:pip install Scipy
-
官网:
二维绘图:Matplotlib
-
简介:重要用于二维绘图、可视化。
-
安装:pip install Matplotlib
-
官网:
-
Matplotlib 画廊:
-
Matplotlib提供的作图展示平台
-
-
常见问题:
-
中文显示:
# 默认为英文plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置黑体
-
负号显示不正常情况:
plt.rcParams['axes.unicode-minus'] = False
-
探索分析:Pandas
-
简介:超强大的数据分析和探索工具,支持类似SQL的数据增、删、查、改,并带有丰富的数据处理函数;时间序列分析;灵活处理缺失数据等。推荐书目Wes McKinney的《利用Pyhton 进行数据分析》
-
安装:pip install Pandas
-
添加 Excel读取功能:
pip install xlrd # Pyhton 读 Excel 功能pip install xlwd # Pyhton 写 Excel 功能
-
-
链接:
-
pandas教程:
-
官网:
-
统计建模:StatsModels
-
简介:注重数据统计建模分析,有R语言的味道,它与Pandas的结合,使Python成为强大的数据挖掘工具
-
安装:pip install StatsModels
-
链接:
-
StatsModels教程:
-
官网:
-
机器学习:Scikit-Learn
-
简介:一个与机器学习相关的库,提供完善的机器学习工具,包括数据预处理、分类、回归、聚类、预测、模型分析等。依赖于Numpy、SciPy、Matplotlib库
-
安装:pip install Scikit-Learn
-
链接:
深度学习:Keras
-
简介:基于Theano的强大深度学习库,让搭建神经网络变得如搭建积木一般简单。
-
安装:安装前需要安装Numpy、Scipy、Theano,其中安装Theano需要GCC编译环境。若需实现GPU加速,需要配置Theano和Keras
-
链接:
-
Theano官网:
-
Keras官网:
-
-
处理语言:Gensim
-
简介:处理语言,如文本相似度、LDA、Word2Vec等
-
安装:需要GCC编译环境
-
pip install gensim
-
-
链接:
-
gensim官网:
-
自然语言处理:
-
数据探索
数据质量分析
脏数据
-
缺失值
-
记录缺失
-
记录中某个字段的缺失
-
-
异常值(离群点)
-
简单统计分析
-
正态分布下的 3x 原则
-
箱型图分析
-
-
不一致的值
-
数据的矛盾性和不相容性
-
原因:数据来源不同...
-
-
重复数据
数据特征分析
分布分析
-
定量的数据分布分析
-
求极差: 极差 = 最大值 - 最小值
-
分组:选择某组距,组数 = 极差 / 组距
-
决定分点:得到分布区间(组段)
-
绘制频率分布直方图:
组段 组中值 x 频数 n 频率 f 累计频率 ...... ..... ...... .... .....
-
-
定性数据分析分布图 :对于定性的变量,可以用饼状图和条形图来进行定性分析
对比分析
-
绝对比较
-
相对比较
-
结构相对数
-
比列相对数
-
比较相对数
-
强度相对数
-
计划完成度相对数
-
动态相对数
-
统计量分析
-
对集中趋势的度量
-
均值: 对于频数分布:
-
中位数
-
众数
-
-
对离中趋势的度量
-
极差:极差最大值最小值
-
标准差:偏离均值的程度
-
变异系数:标准差相对于均值的离中趋势
-
四分位数间距:将数据有小到大排列并分为四分
-
第一个分割点:下四分位数
-
第二个分割点:中位数
-
第三个分割点:上四分位数
-
为观察值的一半,其值越大,差异越大
-
-
周期性分析
贡献度分析 20/80定律
相关性分析
-
直接绘制离散点图
-
绘制里散点图矩阵
-
计算相关系数:二元变量相关分析
-
Pearson 相关系数:要求连续变量的取值服从正态分布
-
-
其中 且 正相关负相关不存在线性关系表示完全线性相关
-
当 时表示存在不同的线性相关不存在线性关系低度线性相关显著线性相关高度线性相关
-
-
Spearman 秩相关系数:
-
也称等级相关系数
-
其中 表示 的秩次, 代表 的秩次。
-
求 秩次:1)将 变量 小到大排列,其排序就为其秩次(注意:当一个变量取相同值时,按所在排序位置取平均值)
-
-
判定系数:相关系数的平方 即 , 越接近1代表 与 相关性越强
-
Pandas的主要数据探索函数
基本统计特征函数 (Pandas)
import Pandas as pd# 生成样本D,一行为1~7,一行为2~8D = pd.DataFrame([range(1,8),range(2,9)])# sum() 按列求和,D可为DataFrame或SeriesD.sum()# mean() 计算样本平均数D.mean()# var() 计算样本方差。D.var()# std() 计算样本标准差D.std()# corr() 计算数据样本的Spearman(Pearson) 相关系数矩阵# D 可为DataFrame,返回相关系数矩阵# method参数为计算方法:支持# pearson: 皮尔森相关系数# Kendall:肯德尔系数# spearman: 斯皮尔系数D.corr(method = 'pearson')S1 = D.loc[0] # 提取第一行S2 = D.loc[1]# S1, S2 为Series 指定计算两个Series之间的相关系数S1.corr(S2,method = 'pearson') # cov() 计算样本协方差矩阵D.cov()S1 = D[0] # 提取第一列S2 = D[1]# S1, S2 为Series 指定计算两个Series之间的协方差S1.cov(S2)# skew() / kurt() : D 的偏度(三阶矩)/峰度(四阶矩)D.skew() / D.kurt()# describle()直接计算样本的基本统计量:均值、标准差、最大值、最小值、分位数...D.descrable()
拓展统计特征函数(Pandas)
-
累计计算(cum)
-
滚动计算(pd.rolling_)
统计作图函数 (Pandas / Matplotlib)
-
准备工作
# 导入作图库import matplotlib.pyplot as plt import numpy as np# 用来显示中文标签plt.rcParams['font.sans-serif'] = ['SimHei']# 正常显示负号plt.rcParams['axes.unicode_minus'] = False# 创建图像区域,指定比列plt.figure(figsize = (7, 5))
-
plot 二维图、折线图
-
功能:绘制二维图、折线图
-
格式:
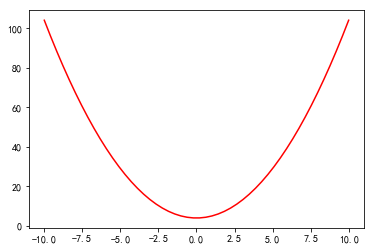
plt.plot(x,y,Str) # plt.plot(x,y,'bp--') 绘制蓝色带星虚线-
Str 指定绘制图形的类型、样式、颜色:
-
'b' # 蓝色'r' # 红色'g' # 绿色'o' # 圆圈'+' # 加号标记'-' # 实线'--' # 虚线x = np.linspace(-10,10)y = x*x + 4plt.plot(x,y,'r-')plt.show()
-
-
-
pie 饼形图
-
功能:绘制饼形图
-
格式:
plt.pie(size) # size是一个列表 -
实例:
# The silces will be ordered and plotted counter-clockwise.labels = 'Frogs', 'Hogs', 'Dogs', 'Logs' # 定义标签# 每一块的比例sizes = [15,30,45,10] # 指定颜色colors = ['yellowgreen', 'gold', 'lightskyblue', 'lightcoral'] # 突出显示,这里仅显示第二块explode = (0, 0.1, 0, 0) plt.pie(sizes, explode = explode, labels = labels, colors = colors, autopct = '%1.1f%%', shadow = True, startangle = 90)plt.axis('equal') # 显示为园(避免比列压缩为椭圆)plt.show()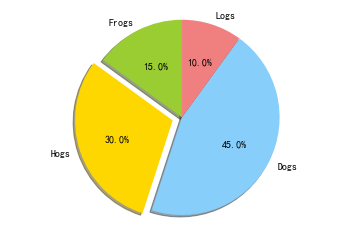
-
-
hist 直方图
-
功能:绘制二维条形直方图,显示数据分布情况
-
格式:
plt.his(x, y) # x 待绘制一维数组 -
实例:
# 1000个服从正态分布的随机数x = np.random.randn(1000)# 分成10组进行绘制直方图plt.hist(x, 10)plt.show()
-
-
boxplot 箱行图
-
功能:绘制样本箱行图
-
格式:
D.boxplot() / D.plot(kind = 'box') -
实例:
# 1000个服从正态分布的随机数x = np.random.randn(1000)# 构造两列DataFrameD = pd.DataFrame([x, x+1]).T# 调用Series内置作图方法画图D.plot(kind = 'box')plt.show()
-
-
D.plot(logx = True) / D.plot(logy = True) # 绘制x或y轴的对数图形
-
实例:
x = pd.Series(np.exp(np.arange(20)))x.plot(label = u'原始数据',legend = True)plt.show()x.plot(logy = True, label = u'对数数据图',legend = True)plt.show()

-
-
D.plot(yerr = error) # 绘制误差条形图
-
实例:
# 定义误差列error = np.random.randn(10)# 均值数据列y = pd.Series(np.sin(np.arange(10)))# 绘制误差图y.plot(yerr = error)plt.show()
-
数据预处理
数据清洗
-
删除无关数据、重复数据、平滑噪声数据、筛选掉与挖掘主题无关的数据,处理缺失值、异常值
缺失值处理
-
方法:删除记录、数据插补、不处理
-
数据插补:
-
均值 / 中位数 / 众数插补
-
最近临插补
-
回归插补:对带有缺失值的变量根据已有数据和与其相关的其他变量数据建立拟合模型来预测变量值。
-
插值插补:利用已知点建立合适的插值函数 与其对应的 求出函数 近似代替。
-
-
插值法:
-
拉格朗日插值法:
-
原理:对于平面上已知 个点可以找到一个 次多项式 ,使此多项式曲线过这 个点。
-
-
牛顿插值法
-
牛顿插值逼近函数:
-
误差函数:
-
-
Hermite插值
-
分段插值
-
样条插值
-
.......
-
异常值处理
-
删除含有异常值记录
-
视为缺失值
-
平均值修正
-
不处理
数据集成
实体识别
-
导致原因:不同数据源的数据的使用时
-
情况:
-
同名异义
-
异名同义
-
单位不统一
-
数据变换
-
数据规范化处理
简单函数变换
-
对原始数据进行某些函数变换,常用变换:
-
平方
-
开方
-
取对数
-
差分运算
-
...
-
规范化
-
消除指标之间量纲和取值范围差异的影响而进行的数据标准化处理
-
方法
-
最小 - 最大规范化(离差标准化)
-
对数据线性变换,将数组映射到 之间
-
公式:
-
-
零一均值规范化(标准差标准化)
-
经过处理的数据均值为0,标准差为1
-
公式:
-
其中 为原始数据的均值, 为原始数据的标准差(用得最多)
-
-
小数定标规范化
-
通过移动属性的小数位,将属性映射到 之间
-
公式:
-
-
连续属性数据离散化
-
原理:在属性取值范围内设定离散划分点,将数据划分为一些离散的区间,并映射到相应的区间取值
-
方法
-
等宽法:对离群点比较敏感,使得某些区间包含数据较多,对决策模型不利
-
等频法:保证每个区间固定的个数
-
(一维)聚类:用聚类算法(如k-means)的方法,将数据合理的划分为几个簇
-
属性构造、小波变换
数据规约
-
降低无效、错误数据对建模的影响,提高建模准确性
-
少量且具有代表的数据增加挖掘效率
-
降低数据储存成本
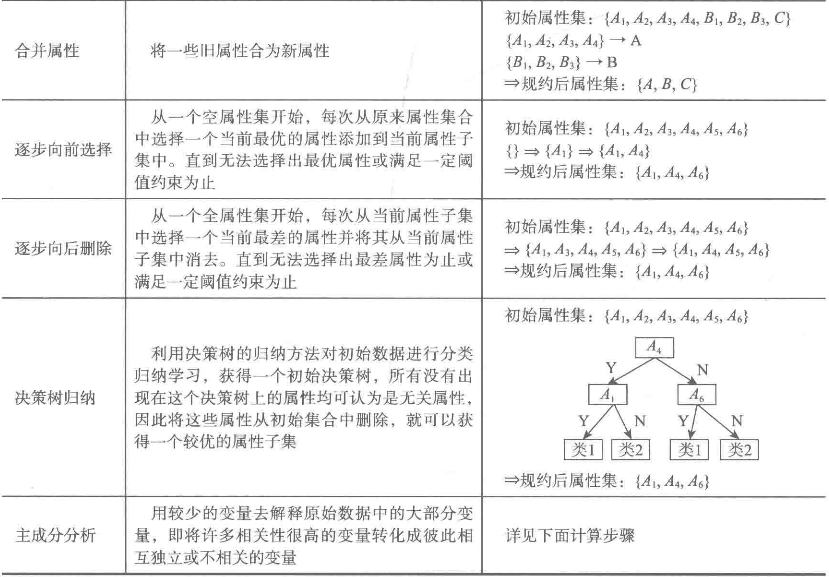
属性规约
-
通过属性的合或删除不相关属性(维)来减小数据维数,提高数据挖掘的效率、降低计算成本
-
常用方法
-
合并属性
-
逐步向前选择
-
逐步向后删除
-
决策树归纳
-
主成分分析
-
数值规约
-
原理:通过选择替代的、较小的数据来减小数据量
-
方法:
-
直方图
-
聚类
-
抽样
-
参数回归
-
python主要数据预处理函数

挖掘建模
分类与预测
-
在已知类别的基础上,通过算法得到的规则对未知的数据集进行分析,归类的方法
回归分析
-
适用于:确定预测数据(数值型)和其他变量间相互依赖的定量关系
-
统计学方法:
-
线性回归
-
条件:变量间为线性关系
-
描述:对一个或多个自变量和因变量之间的线性关系进行建模,可用最小二乘法求解模型系数
-
-
非线性回归
-
条件:变量间不是线性关系
-
描述、
-
转化为线性关系
-
或用非线性最小二乘法求解
-
-
-
-
Logistics回归
-
条件:因变量为0 - 1 两种取值
-
描述:
-
-
岭回归
-
条件:参与建模的自变量之间具有多重共线性
-
描述:改进的最小二乘估计方法
-
-
主成分回归
-
条件:参与建模的自变量之间具有多重共线性
-
描述:改进的最小二乘估计方法,它是参数估计的一种有偏估计,可消除自变量间的多重共线性
-
-
偏最小二乘法回归
-
....
决策树
-
采用自顶向下的方式,在内部节点进行属性值比较,并根据不同属性值从该节点向下分支,最终得到决策树规则。
-
常用算法:
-
ID3算法
-
C4.5算法
-
CART算法
-
贝叶斯网络
-
置信度网络,目前为不确定知识表达和推理领域的最有效模型之一。
人工神经网络
-
相关算法:
-
BP神经网络
-
LM神经网络
-
RBF径向基神经网络
-
FNN模糊神经网络
-
GMDH神经网络
-
ANFIS自适应神经网络
-
支持向量机
-
通过某种非线性映射,将低维非线性可划分为高维的线性可分、在高维空间进行线性分析的方法。
Python分析/预测模型
-
逻辑回归
-
SVM
-
决策树
-
随机森林
-
朴素贝叶斯
-
神经网络

聚类分析
-
在没有给定划分的情况下,根据数据的相似度进行划分的一种方法
划分(分裂)方法
-
K-Means(K-均值)
-
K-MEDOIDS(K-中心点)
-
CLARANS(基于选择的算法)
层次分析方法
-
BIRCH(平衡迭代规约和聚类)
-
CURE(代表点聚类)
-
CHAMELEON(动态模型)
基于密度的方法
-
DBSCAN(基于高密度连接区域)
-
DENCLUE(密度分布函数)
-
OPTICS(对象排序识别)
基于网格的方法
-
STING(统计信息网络)
-
CLIOUE(聚类高维空间)
-
WAVE-CLUSTER(小波变换)
基于模型的方法
-
统计学方法
-
神经网络方法
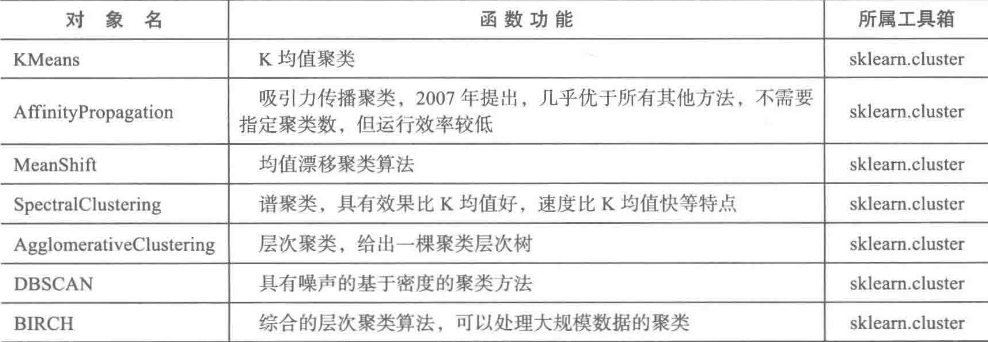
Python聚类主要函数
关联规则
-
寻找属性间,项与项间的关联关系
常用算法
-
Apriori算法
-
通过连接产生候选项及其支持度然后通过剪枝生成频繁项集
-
-
FP-Tree
-
减少了Apriori算法频繁访问数据集的缺陷,提出不产生候选频繁项集的方法
-
-
Eclat算法
-
深度优先,采用垂直数据表示形式,在概念格理论的基础上利用基于前缀的等价关系将搜索空间划分为较小的子空间
-
-
灰色关联法
-
分析和确定各因数间的影响程度或若干个子因素(子序列)对主因素(母序列)的贡献度而进行的分析方法
-
时序模式
常用模型

Python主要时序模式算法